-
- Accueil
- NSI
- La représentation des caractères
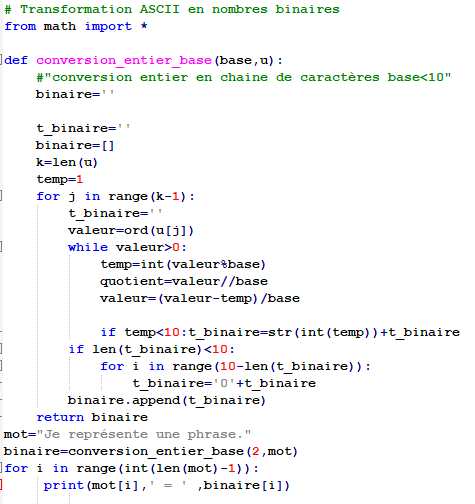
- Représenter des textes (script python)
- Décoder un texte représenté en ASCII binaire
Codage des textes :.
.
La représentation des caractères
.
Un texte est une suite de caractères, aux lettres minuscules et majuscules, aux chiffres, aux signes de ponctuation et aux symboles mathématiques.Pour représenter ces caractères, on attribue un nombre à chacun.
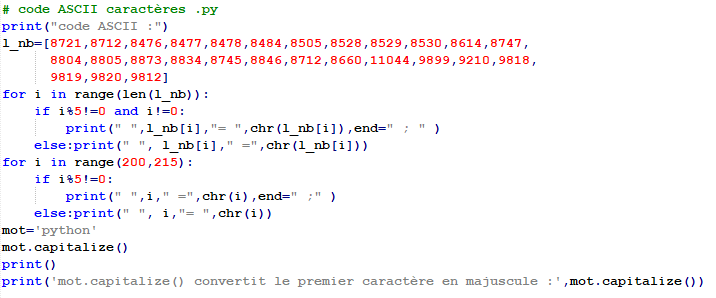
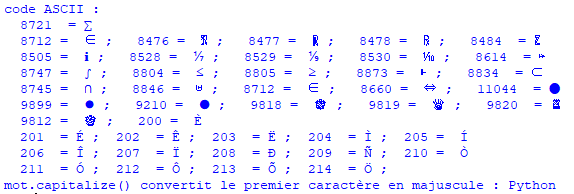
Le code ASCII, par exemple, attribue le nombre 65 à la lettre « A », le nombre 66 à la lettre « B », le nombre 97 à la lettre « a » et le nombre 98 à la lettre « b ». Il représente 95 caractères : les 26 lettres minuscules, les 26 lettres majuscules, les 10 chiffres, les 32 symboles ! ~# $ % & ’ ( ) { }[ ] @ < > = ? ; : / + - et 1 signe d’espace. Il représente aussi 33 autres symboles de mise en page, par exemple le retour chariot qui signale la fin de la ligne et le saut de page qui signale le passage à la page suivante.Le code ASCII représente donc \(95\ + \ 33\ = \ 128\ = \ 2^{7}\) caractères, par des nombres qui peuvent eux-mêmes être représentés en binaire par des mots de sept bits. Ils sont en fait représentés par des mots de huit bits, le premier étant toujours un zéro.
Le code ASCII était à l’origine conçu pour des textes écrits en anglais, comme l’indique son nom, American Standard Code for Information Interchange.
Il n’est pas adapté pour représenter des textes écrits dans d’autres langues, même celles qui, comme le français, utilisent l’alphabet latin, car ces langues utilisent des accents, des cédilles et autres signes diacritiques. C’est pourquoi on a tout d’abord conçu une extension du code ASCII,
le code latin-1, qui contient 191 caractères. Aux 128 caractères du code ASCII, qui sont représentés comme en ASCII, s’ajoutent les lettres « é », « É », « è », « ç », « æ », « ñ », « ö », etc. qui permettent de représenter les textes écrits dans la plupart des langues d’Europe de l’Ouest, même si, pour le français, le « œ » a été oublié.
Le code latin-2, a été proposé pour d’autres langues.
.
Le format universel : Unicode.
.
Unicode recense près de 110 000 caractères et associe un nom et un numéro à chacun. A priori, ce numéro se code sur 32 bits.
Unicode existe en plusieurs déclinaisons :
UTF-32 : chaque caractère est ainsi exprimé sur 32 bits.
UTF-8 : Les caractères les plus courants sont exprimés sur 8 bits et les moins courants sur 16, 32 ou 64 bits.
Cependant, tous ces formats reposent sur une même idée : associer un nombre, c’est-à dire un mot binaire, à chaque caractère. Tous ces formats sont accessibles sur le Web.
.
Représenter des textes (script python)
.
.
Décoder un texte représenté en ASCII binaire
.
On découpe la suite de bits en octets, on traduit chaque octet en décimal, puis on cherche en utilisant une table, le caractère exprimé par chacun de ces nombres.
:.
Exemple 4
.
Trouver le texte représenté en ASCII binaire par la suite de bits :
000100101000011001010000100000000111001000011001010001110000000111001000111010010001110011000110010100011011100001110100000110010100001000000001110101000110111000011001010000100000000111000000011010000001110010000110000100011100110001100101
On commence par découper la suite de bits en octets :
01000011 00100111 01100101 01110011 01110100 00100000 01100110 0001001010 0001100101 0000100000 0001110010 0001100101 0001110000 0001110010 0011101001 0001110011 0001100101 0001101110 0001110100 0001100101 0000100000 0001110101 0001101110 0001100101 0000100000 0001110000 0001101000 0001110010 0001100001 0001110011 0001100101
Chaque octet représente un nombre entier :
74, 101, 32, 114, 101, 112, 114, 233, 115, 101, 110, 116, 101, 32, 117, 110, 101, 32, 112, 104, 114, 97, 115, 101